What is, in science, the value of a value? In physics, this depends on how certain you are of this value. As quantities are determined using experiments, and these experiments are subject to error and uncertainties, the value can only be determined to some degree. We are never 100% sure of the exact value. Therefore, values are given with their uncertainty: = 9.81 ± 0.01 m/s. So how do we determine to what extent a value is certain?
Errors and uncertainty¶
Uncertainties in values can arise from the precision of the instruments used in the experiment, errors made by the person doing the experiment, vibrations, temperature effects, and fundamental errors related to the phenomenon being studied. Some of these uncertainties can be reduced, others just have to be accepted. Whatever their cause, these effects influence experiments and their outcomes of the experiments and therefore influence the uncertainty in the quantities we want to determine.
Gaussian noise¶
Random errors will usually conform to a Gaussian distribution. The probability of an error of some sort occurring can be calculated through:
In this function, is the average value of the error, the standard deviation, a measure of the spread of the error, is the value of the error. In section Repeating measurements we assume that the errors we have to deal with are following a Gaussian distribution. The graph below shows what Gaussian noise looks like, following the probability density function shown in the second graph.
Source
import matplotlib.pyplot as plt
import numpy as np
import math
from scipy.optimize import curve_fit
from ipywidgets import interact
from scipy import special
from sympy import init_printingSource
mu = 0
sigma = 25
N = 10000 #number of data points
y = np.random.normal(mu,sigma,N) #noise creation
x = np.linspace(1,N,N)
plt.figure()
plt.plot(x[:1000],y[:1000],'k.')
plt.show()
print("""(a) A scatter plot of the noise. Although most data are in between -25 and 25, one can find data points with values >50.""")
plt.hist(y,bins = 50) #bins chosen relatively large, but at random
plt.show()
print("""(b) A histogram of the noise. One can easily see that roughly 2/3 of the data is within µ ± σ and 90% """)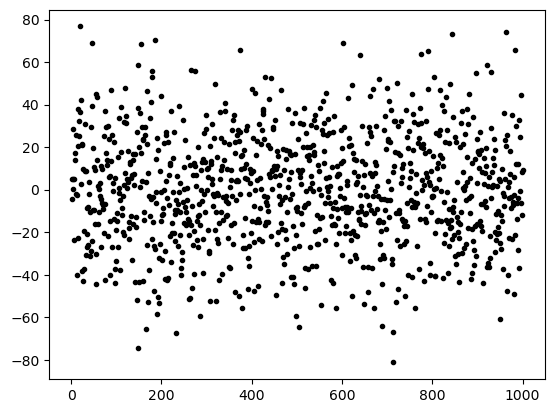
(a) A scatter plot of the noise. Although most data are in between -25 and 25, one can find data points with values >50.
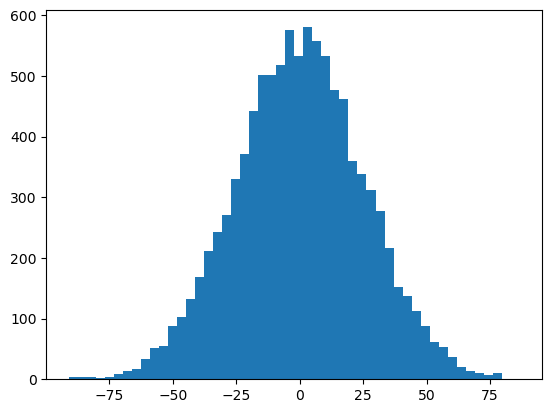
(b) A histogram of the noise. One can easily see that roughly 2/3 of the data is within µ ± σ and 90%
Systematic error¶
If there is, e.g., a calibration error of the instrument, a systematic error occurs with each and every measurement. If your ruler starts at 0.2 cm but you didn’t notice, this will cause a systematic error.
Figure 1:A not calibrated instrument will probably result in a systematic error.
If you suspect a systematic error, you can look for it using e.g. Python. If the to be fitted function is and you suspect a systematic error in the distance, , you can try to fit the function . You still have to validate whether the systematic error is within a sensible range and whether there is indeed a systematic error.
Figuring out whether you have the problem of a systematic error can be done by analysing the residuals. If are the values of your measurements at certain point , and is the value of the fitted function at the same point , the residuals are defined by:
Source
# Code to show the influence of a systematic error (in x)
#create data
x = np.linspace(0,10,11)
def quadratic(x):
return 4.3*(x+.6)**2 + np.random.normal(0,1)
y= quadratic(x)
#curvefit without systematic error
def solvex1(x,a):
return a*x**2
pval_1, pcov_1 = curve_fit(solvex1,x,y)
y2 = solvex1(x,pval_1[0])
plt.plot(x,y,'r.')
plt.plot(x,y2,'--')
plt.show()
print("(a) A curve fit using least square method without compensation for a systematic error $y = a \cdot x^2$")
#curvefit with system
def solvex2(x,a,b):
return a*(x+b)**2
pval_2, pcov_2 = curve_fit(solvex2,x,y)
y3 = solvex2(x,pval_2[0],pval_2[1])
plt.plot(x,y,'r.')
plt.plot(x,y3,'--')
plt.show()
print(f"(b) A curve fit using least square method with compensation for a systematic error $y = a \cdot (x + \Delta x)^2$")
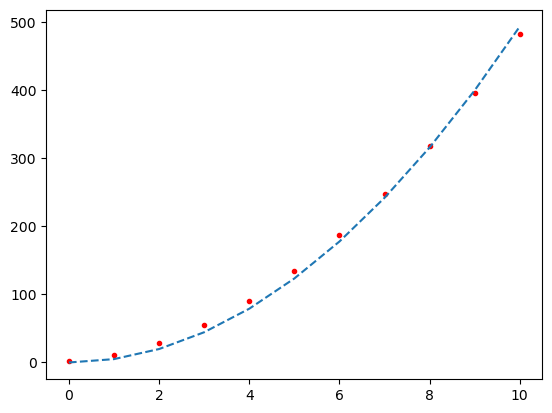
(a) A curve fit using least square method without compensation for a systematic error $y = a \cdot x^2$
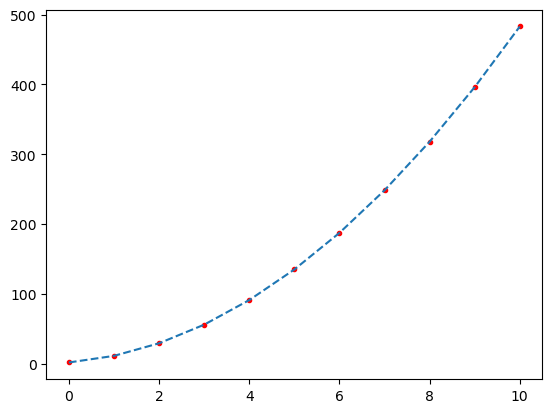
(b) A curve fit using least square method with compensation for a systematic error $y = a \cdot (x + \Delta x)^2$
Repeating measurements¶
Repeating a measurement helps us determine the ‘exact’ value. The best estimate of the exact value is the mean:
in which is a measurement and is the number of repeated measurements.
In the analysis of experimental data, an important parameter is the standard deviation, . If the experiment is done again, the chance that the value is between is 2/3. The standard deviation is calculated by
There is another way to determine the standard deviation more quickly, but this is somewhat less accurate (the rough-and-ready approach). The standard deviation is roughly .
If the same experiment is repeated, the average value will differ slightly each time. This means that their is an uncertainty within the average. This parameter is called the standard deviation of the mean, :
This uncertainty tells you that if the entire experiment is repeated, there is a 2/3 change that the average value is within .
The average, standard deviation and standard error as function of noise samples. It can be seen that the average and standard deviation do not change much and only get better determined. The standard error decreases with .
Source
mu = 0
sigma = 25
N = 10000 #number of data points
y = np.random.normal(mu,sigma,N) #noise creation
x = np.linspace(1,N,N)
#creates and fills list for average,std, and error against the number of data points used
av_n = []
std_n = []
error_n = []
for n in range(1,N+1):
av_n.append(np.mean(y[:n]))
std_n.append(np.std(y[:n]))
error_n.append(std_n[-1]/np.sqrt(n))
plt.figure()
plt.xlabel('N')
plt.ylabel('$\overline{x}$')
plt.plot(x, av_n, "b.")
plt.show()
print("""(a) The average value of N noise samples. It can be clearly seen that the value converges to 0.""")
plt.figure()
plt.xlabel('N')
plt.ylabel('$\sigma_x$')
plt.plot(x, std_n, "b.")
plt.show()
print("""(b) The standard deviation of N noise samples. It can be clearly seen that the value converges to 25.""")
plt.figure()
plt.xlabel('N')
plt.ylabel('$\mu_x$')
plt.plot(x, error_n, "b.")
plt.show()
print(""" (c) The standard error of N noise samples. It can be seen that the uncertainty decreases.""")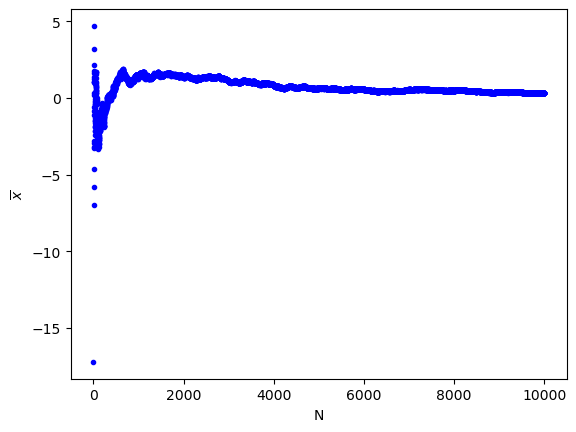
(a) The average value of N noise samples. It can be clearly seen that the value converges to 0.
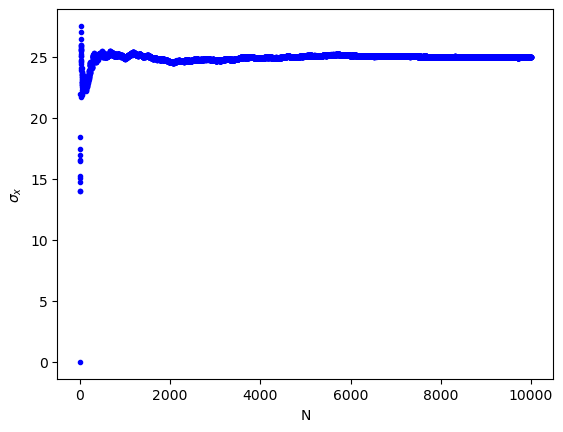
(b) The standard deviation of N noise samples. It can be clearly seen that the value converges to 25.
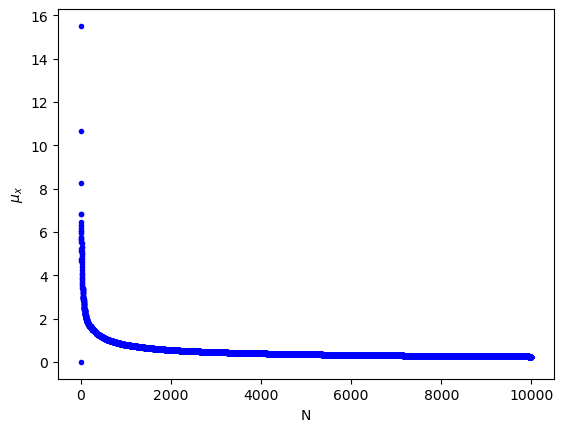
(c) The standard error of N noise samples. It can be seen that the uncertainty decreases.
Chauvenet’s criterion¶
What if a measurement is repeated ten times, and one value is very different from the rest? Can it just be discarded? To decide whether a value can be discarded, one can use the theory above and extend it. To start, you calculate the mean and the standard deviation. Subsequently you calculate the occurrence of the outlier , using the error function: . You can use this site to use the error function
If is smaller than 0.5, the measurement may be discarded. Disregarding a measurement should be mentioned in the report! You also have to calculate a new mean value and uncertainty as the data set has changed.
Error Function(s)¶
There are two types of error functions, the and the . Which are defined like this:
The easiest way is to use the error function is to import it from the scipy package. A plot of both functions can be seen in the graph below.
Source
#erf(x)
x = np.linspace(-3, 3, 1000)
plt.plot(x, special.erf(x))
plt.xlabel('$x$')
plt.ylabel('$erf(x)$')
plt.xlim(-3,3)
plt.show()
#Erf(x_out, x_bar, sigma)
# parameters
sigma = 5
x_bar = 15
def Erf(x, x_bar, sigma):
return 0.5*(1+ special.erf((x-x_bar)/(np.sqrt(2)*sigma)))
x = np.linspace(0, 30, 10000)
plt.plot(x, Erf(x, x_bar, sigma))
plt.xlabel('$x$')
plt.ylabel(r'$Erf(x,\bar{x},\sigma)$')
plt.xlim(0,30)
plt.show()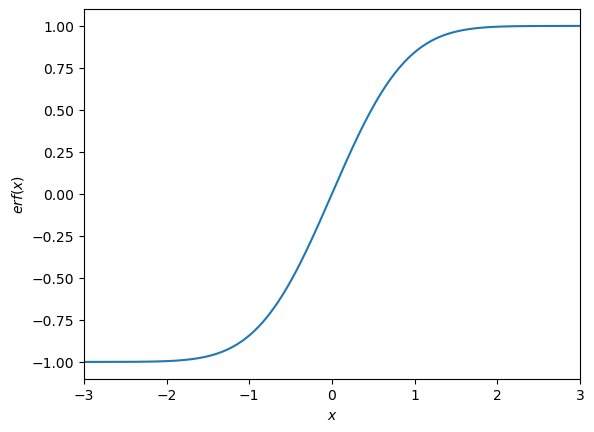
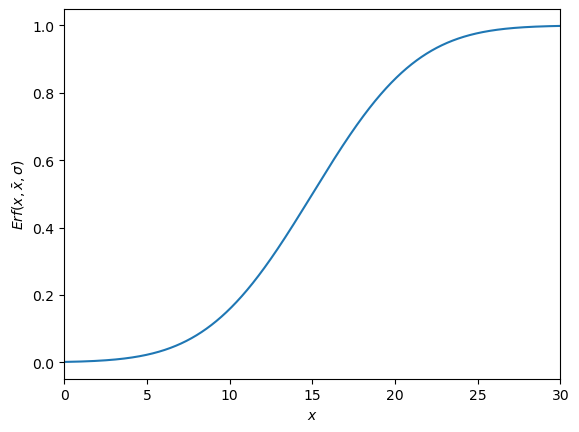
What can be seen is that the function is basically a shifted version of the the function. As by dividing it by two and adding 0.5 shifts it up and makes it smaller. The shifts it so that the mean is at the center of the function and dividing it by ‘stretches’ the function so that it is in the right range. What one also can see if that when you have an outlier which is higher than the mean the will return a value higher than 0.5 which will always result in a value which cannot be discarded. When this happens you have to do , this you multiply by , or one can use:
This you still have to multiply by (not by 2).
Significant figures¶
Significant figures are essential to physics. Most of you are probably already familiar with them. Significant figures are important because they indicate the uncertainty of a value. The number of figures after the comma of and are always the same!
A brief reminder on how to determine the number of significant figures:
All non-zero digits are significant: m/s has four significant figures.
All zeroes between non-zero digits are significant: mol has nine significant figures.
Zeroes to the left of the first non-zero digits are not significant: 0.51 MeV has two significant figures.
Zeroes at the end of a number to the right of the decimal point are significant: C has three significant figures.
If a number ends in zeroes without a decimal point, the zeroes might be significant: 270 might have two or three significant figures.
Rules¶
For most numbers, it is not hard to round of to the correct number of significant figures:
However, always rounding up 0.5 to 1 will result in a higher rounded value. So the rule is: even numbers before a 5 are cut, odd numbers before a 5 are rounded:
With adding and/or subtracting the least number of figures after the comma is decisive. This also means that the total number of significant figures might change:
With multiplication or division the least number of significant figures is decisive:
This last example needs perhaps a further explanation: 5 / 2.00 = 2.5. However, one figure is allowed. 2 is an even number, so the last decimal is cut.
Error propagation¶
If the uncertainty is known for one value, and that value is used in an equation, the result of that equation will also have some degree of uncertainty. Often, we have multiple variables each having their own degree of uncertainty. There are two ways to calculate this uncertainty: the functional approach, which involves propagating throughout the function, and the calculus approach, which is a linearization of the function.
Functional approach¶
When a function only depends on a single variable , the uncertainty can be calculated using:
When a function depends on multiple independent variables, like for instance (P = UI), the uncertainty needs to be calculated separately for each value using (22), (23) and (24). This method can be used for any number of independent variables.
Calculus approach¶
The calculus approach uses a linearization to determine the effect a measured value has on the value . For a single variable function the uncertainty in is given by:
The linearization will result in an error that becomes noticeable when the error of is relatively big and there is a lot of curve in the function in that area of .
The general form for the calculus approach of Z(,...) with uncertainties (), (),... is given in (29).
An example of the calculus approach for is given in (30).
Resulting in (31).
Dividing both sides of the equation by yields us a simple and direct equation for :
More general, for a function the uncertainty in can be calculated by:
Advantages of both methods¶
The advantage of the functional approach is that it does not use the approximation of a linearization and is therefore more accurate. This is usually only noticeable when the uncertainty of a measured value is large and the function has a lot of bend. The advantage of the calculus approach is that it gives a clearer relation between the uncertainty of a variable and how it propagates into the uncertainty of the determined value
Error in function fit¶
You have plotted your data () with their uncertainties and are now looking for a function that best describes the data set (Note: earlier we talked about a measurement and function , this is the same principle). You make an educated guess (or use a theoretical framework) to predict the function. An estimate of how well your function predicts the data is given by:
If there is a perfect match between data and fit, the sum will be 0. Most curve fitting tools use this principle and are looking for the values for the variables for which this sum is minimal. A good fit goes at least through 2/3 of the error bars.
We can learn a lot about our data by looking at the residuals: . There might still be a detectable pattern, hidden in the noise. Using Python is an excellent way to find out what your data is telling you...
from ipywidgets import interact
import ipywidgets as widgets
import numpy as np
import matplotlib.pyplot as plt
# Data
x = np.linspace(0, 11, 10)
y = np.random.normal(0, 2, 10)
# Function
def f(a):
chi_square = np.sum((y - a) ** 2)
# Subplots
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Left: Data and fit
axes[0].plot(x, a * np.ones(len(x)), 'r--', label=f'a = {a:.1f}')
axes[0].plot(x, y, 'k.', label='Data')
axes[0].set_title("Data en lijn")
axes[0].legend()
# Right: Chi-square as function of a
a_values = np.linspace(-5, 5, 100)
chi_square_values = [np.sum((y - a_val) ** 2) for a_val in a_values]
axes[1].plot(a_values, chi_square_values, 'b-', label="chi^2(a)")
axes[1].plot(a, chi_square, 'ro', label=f'Current chi^2 = {chi_square:.2f}')
axes[1].set_title("chi^2 als functie van a")
axes[1].set_xlabel("a")
axes[1].set_ylabel("chi^2")
axes[1].legend()
plt.tight_layout()
plt.show()
# Interactieve widget
interact(f, a=widgets.FloatSlider(min=-5, max=5, step=0.1, value=0))
<function __main__.f(a)>Poisson distribution¶
We covered so far the Gaussian distribution. However, there is also the Poisson distribution which is important when counting, e.g., radioactive decay. The Poisson distribution is a discrete probability distribution.
The chance of counting events in a certain amount of time, with the expected value is given by:
The standard deviation of the Poisson distribution is given by the square root of the expected value: ().
The shape of the function resembles the Gaussian distribution. This is not really strange as for large numbers of the Poisson distribution indeed becomes similar to the Gaussian distribution. However, for small numbers of , the Poisson distribution is not symmetrical.
Source
#poison plot
lamb = 20 #lambda
k = np.arange(0,2*lamb+1,1)
def Poisson_prob(k, lamb):
return np.exp(-lamb)*np.power(lamb, k, dtype = "float")/special.factorial(k)
plt.figure()
plt.plot(k, Poisson_prob(k, lamb), "b.")
plt.xlim(0,2*lamb)
plt.show()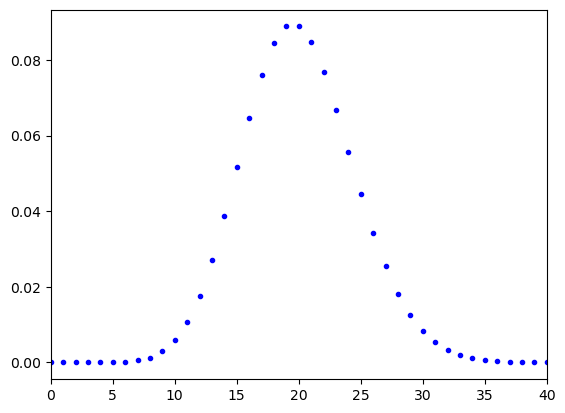
Practice¶
These questions will help you digest the information described above. The answers can be found at the end of this manual. Do not forget to look at the python assignments!
Determine the mean, standard deviation and standard error of the following data sets:
0.10; 0.15; 0.18; 0.13
25; 26; 30; 27; 19
3.05; 2.75; 3.28; 2.88
Use Chauvenet’s criterium to find out whether 19 in the previous task can be considered a real outlier.
Eric weighed a small cubic box. Its mass was 56 ± 2 grams. The box has sides of 3.0 ± 0.1 cm.
Determine the gravitational force working on this box.
Determine the volume of this box.
Determine the density of this box.
Evaluate whether the density is determined precisely enough to determine the material of the box.
During an experiment the electrical power of a light bulb is determined by measuring the voltage over and current through the light bulb. The measurements are displayed in the table below:
| (V) | (V) | (mA) | (mA) |
|---|---|---|---|
| 6.0 | 0.2 | 0.25 | 0.01 |
Measurements on a light bulb
Determine the electrical power of the light bulb.
Determine the resistance of the light bulb.
If you could determine either voltage or current more precise, which would you choose and why?
In the table below are the values given for constants and . Determine in each of the following exercises the value and uncertainty of , use both the calculus and the functional approach. Describe in each exercise which uncertainty has the biggest influence on .
| B | C | ||||
|---|---|---|---|---|---|
| 5 | 0.1 | 500 | 2 | 1 | 0.1 |
In the table below are values given for and .
| x | |||
|---|---|---|---|
Calculate the value and uncertainty of .
Do the same as in the previous exercise, but now calculate for and . What do you notice?
Now let be and take and , what do you notice?
Assignment¶
The final assignment for Measurement and uncertainty consists of a Python Jupyter Notebook with questions. You are allowed to bring code, this manual, notes. If it concerns a morning session the assignment is available from 8:45. Handing in your work, using Brightspace, can be done until 11:30. If it concerns a afternoon session, the assignment is available from 13:45. Handing in your work, using Brightspace, can be done until 16:00. This information will be provided before the test as well.